Microsoft Fabric’s Bronze-Silver-Gold Pattern: Real-World Implementation Guide
Microsoft Fabric empowers modern data teams by offering a unified platform to build scalable and organized data pipelines. A foundational design pattern within Fabric’s ecosystem is the Bronze-Silver-Gold data architecture. This layered approach simplifies data flow management, supports modular transformation, and enables consistent delivery of trusted insights across the organization.
In this blog, we’ll explore each layer—Bronze, Silver, and Gold—with practical use cases and show how you can structure these layers effectively in Microsoft Fabric.
Understanding the Bronze-Silver-Gold Architecture
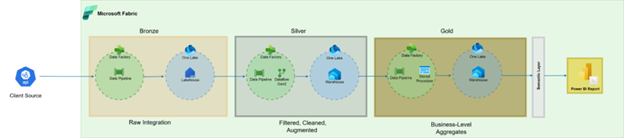
This tiered approach categorizes data based on its stage in the transformation journey—from raw input to business-ready intelligence.
| Layer | Purpose | Data Quality | Transformation Level |
|---|---|---|---|
| Bronze | Initial raw data from source | Low | None to minimal |
| Silver | Cleaned and standardized datasets | Medium | Moderate |
| Gold | Refined, aggregated business output | High | Advanced |
Bronze Layer: The Raw Ingestion Zone
Role:
This layer acts as a landing zone for source data. It captures unprocessed inputs directly from systems like databases, APIs, logs, or flat files—preserving full lineage and original structure.
Key Characteristics:
- Stores data without any transformations
- Ideal for historical tracking and debugging
- Enables reprocessing in case of upstream issues
How to Implement in Fabric:
- Load files to the Files/raw/ folder in a Lakehouse
- Use Pipelines or Dataflows Gen2 for ingestion
- Common formats: CSV, JSON, Parquet
Real-World Scenario:
A retail chain uploads daily sales CSVs from 100+ stores. These logs include inconsistencies, such as irregular timestamps and incomplete fields. Bronze keeps them intact for traceability.
Silver Layer: The Standardization Stage
Role:
At this stage, raw data undergoes cleansing and enrichment. Data from the Bronze layer is converted into structured, reliable tables.
Key Characteristics:
- Deduplicates and standardizes formats
- Fixes data quality issues (e.g., null handling, type casting)
- Combines with lookup or reference data
How to Implement in Fabric:
- Read from Bronze and write to Tables/silver_* tables
- Use Spark Notebooks, PySpark, or T-SQL
- Organize domain-specific cleaned tables: silver_sales, silver_customers, etc.
Real-World Scenario:
The retail team enhances their Bronze sales data by:
- Removing duplicate transactions
- Formatting inconsistent timestamps
- Merging store metadata like city and region
This makes the data more reliable for downstream consumption.
Gold Layer: The Analytical Output Zone
Role:
This is where data is modeled for analytics. The Gold layer delivers KPI-driven, business-aligned insights used in reports and dashboards.
Key Characteristics:
- Designed for consumption by BI tools
- Contains aggregated or calculated metrics
- Tied to business logic and performance goals
How to Implement in Fabric:
- Output to curated tables like gold_sales_summary, gold_customer_lifetime
- Build Power BI semantic models on top
- Use DAX for metric definitions
Real-World Scenario:
- From the cleansed Silver data, the retail team creates:
- Regional daily revenue summaries
- Monthly category sales trends
- Customer loyalty segments
These datasets power leadership dashboards for real-time performance tracking.
Fabric Implementation Best Practices:
| Area | Recommendation |
|---|---|
| Naming Convention | Use prefixes like bronze_, silver_, and gold_ for clarity and traceability |
| Data Lineage | Maintain transformation history using Dataflows Gen2 or detailed notebook logs |
| Quality Checks | Implement validations especially in the silver layer to ensure reliability |
| Access Control | Restrict access—Bronze for engineers, Gold for analysts |
Conclusion:
The Bronze-Silver-Gold data architecture is a cornerstone of scalable data solutions in Microsoft Fabric. By layering data transformation steps, organizations can build clean, traceable, and reusable data products that align with both operational needs and analytical goals. This approach enhances cross-team collaboration, data governance, and business agility—making your data ecosystem more resilient and insightful.