SSIS Error Handling in Destination Components: When to Fail, Redirect, or Ignore
If you’ve worked with SSIS (SQL Server Integration Services), you know that loading data into a destination—whether it’s a SQL table, flat file, or cloud service—is usually the last step in your data flow. But it’s also the spot where things can fall apart fast if something doesn’t go as expected.
That’s where error-handling comes in.
SSIS gives you three main ways to handle errors in destination components:
- Fail on Error
- Redirect Rows to Error Output
- Ignore Error
Let’s break down what each one does, and—more importantly—when you should use them.
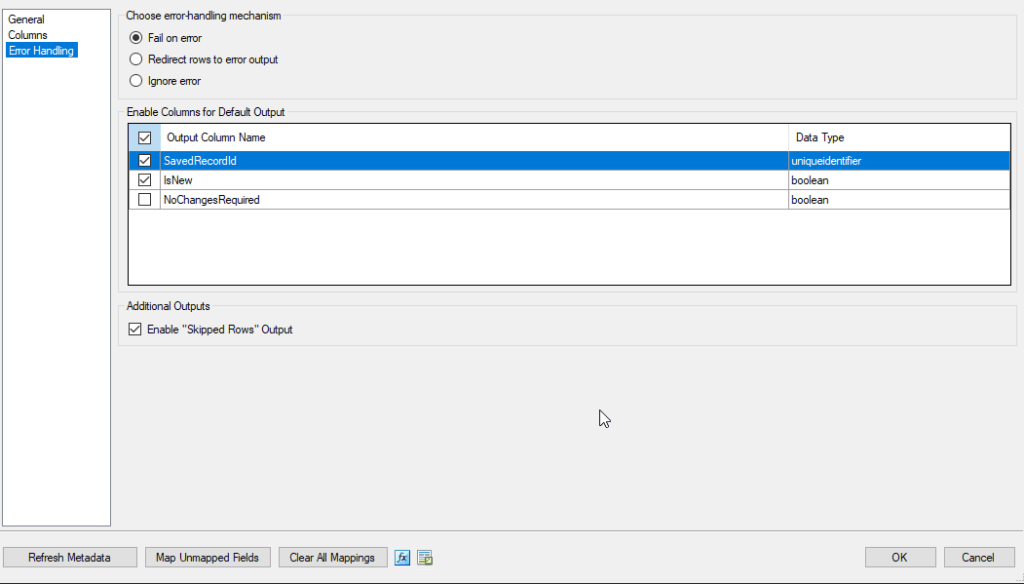
Fail on Error
This option immediately halts the data flow task if any error is encountered while writing to the destination.
Behavior:
- No error rows are passed forward.
- The SSIS engine treats the component as failed, and any connected tasks are canceled.
- You must handle the failure using event handlers or fail the entire package.
When to use:
- Performing critical updates/inserts, and data integrity is a top priority.
- Need the process to halt so issues can be investigated immediately.
- Running the task in a test or development environment and want strict visibility into every failure.
Use cases:
- Writing to production systems with regulatory or compliance requirements.
- Loading records where every record must be validated.
- Early-stage ETL debugging and unit testing.
Risks:
- One error stops the show—good data is not loaded.
- May not scale well with large or inconsistent data sources.
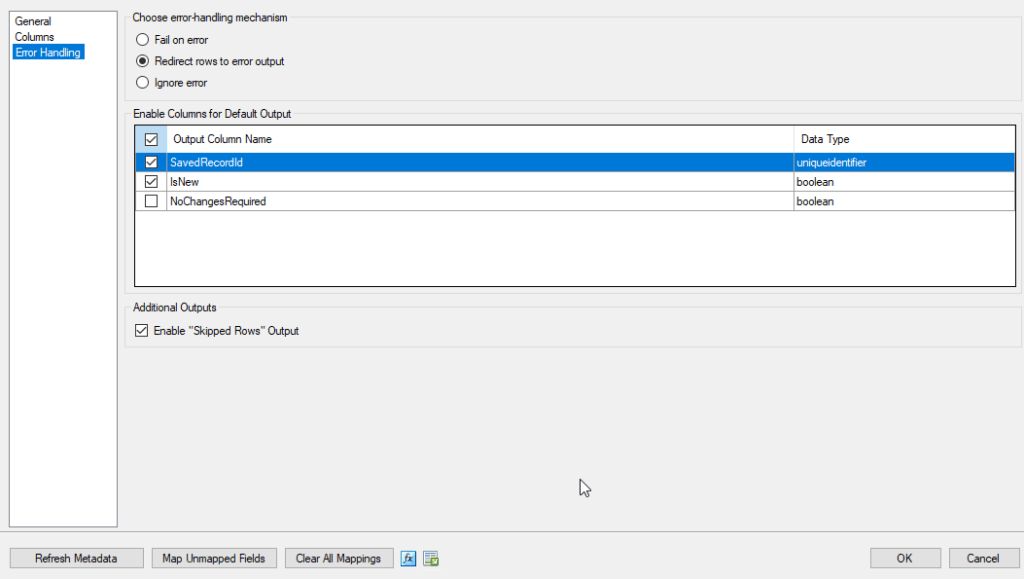
Redirect Rows to Error Output
Only the problematic records are sent to an error output, allowing the rest of the data to be processed successfully. You can then log, store, or correct the failed rows.
Behavior:
- SSIS generates two outputs from the destination:
- Success Output
- Error Output – contains failed rows, error codes, and descriptions.
- You can configure Error Code and Error Column metadata to identify the problem.
When to use:
- You want to handle errors gracefully without stopping the entire process.
- You need to analyze failed records separately and reprocess them later.
- Useful for production workloads where maximum throughput is desired with minimal disruption.
Use Cases:
- Importing customer data where some records might violate constraints (e.g., NULLs in non-nullable fields).
- Merging datasets from different sources with varying schemas.
- Scheduled loads where minor issues shouldn’t stop processing.
Risks:
- Redirected rows can quietly pile up if not monitored.
- If the error path is not handled, the package may still fail.
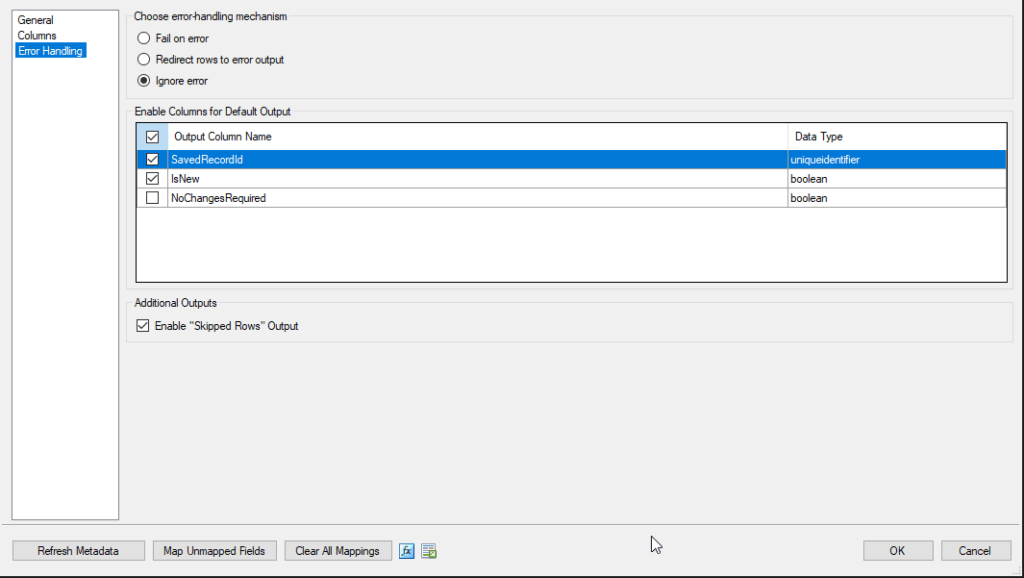
Ignore Error
The component simply skips the failed rows and does not raise an error or output them anywhere.
Behavior:
- Failed rows are not redirected.
- No error info is passed through; error is essentially suppressed.
- You lose visibility in how many rows were skipped and why.
When to use:
- You don’t care about occasional failed rows (e.g., during mass updates where you expect some outdated/locked records).
- The source data is non-critical or already filtered for issues.
- You’re doing a temporary migration or cleanup job where precision isn’t vital.
Use Cases:
- Loading test or training datasets.
- Archiving legacy data with known issues.
- Temporary jobs where accuracy is not a priority.
Risks:
- No logs = no traceability of what was lost.
- Can mask real data issues, especially dangerous in production.
- Poor choice for regulated, auditable environments.