Guide to Direct Lake in Microsoft Fabric
Data moves fast, and businesses need to keep up. Whether it’s tracking retail inventory or monitoring financial transactions, staying ahead requires analytics that are both lightning-fast and nearly up to the moment. Enter Direct Lake Storage Mode in Microsoft Fabric—a revolutionary approach that delivers high-performance analytics. In this guide, we’ll explore what Direct Lake is, how it works, its benefits, and how you can use it to supercharge your analytics workflows. First, we will see exiting storage modes.
What Are Storage Modes in Power BI?
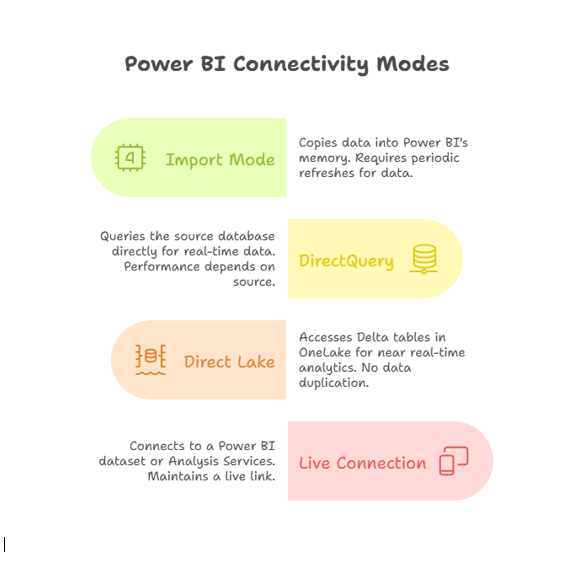
Storage modes in Power BI and Microsoft Fabric determine how data is stored and queried for reports and analytics. There are four main modes:
- Import Mode: Copies data into Power BI’s in-memory model for blazing-fast queries. The downside? It requires periodic refreshes, so data may not always be fresh.
- DirectQuery: Queries the source database directly, ensuring real-time data. However, performance depends heavily on the source system’s speed and optimization.
- Direct Lake: A new mode exclusive to Microsoft Fabric. It accesses Delta tables in OneLake for near real-time analytics without duplicating data.
- Live Connection: Connects to a Power BI dataset or Analysis Services model, leveraging its in-memory cache for fast queries while maintaining a live link to the source.
Each mode has its strengths, but Direct Lake stands out by combining speed, freshness, and efficiency.
What Is Direct Lake in Power BI?
Direct Lake is a cutting-edge storage mode in Power BI, designed for handling massive datasets with ease. It’s tailored for semantic models (the structure defining how data is used for analysis) stored in a Microsoft Fabric workspace.
Here’s how it works: instead of copying data into Power BI (which can be slow and resource-heavy), Direct Lake connects directly to Delta tables stored in OneLake, Fabric’s centralized data hub. Delta tables use the Parquet format, which is highly efficient for columnar data storage, enabling rapid loading into memory.
Once loaded, Power BI’s VertiPaq engine takes over, delivering the same lightning-fast performance as Import Mode. The key difference? There’s no data duplication—Direct Lake points to the latest files in OneLake, keeping your reports fresh and your storage lean.
Why Direct Lake Matters
Traditional storage modes force you to choose between speed and data freshness. Import Mode is fast but static, DirectQuery is fresh but can be slow, and Live Connection relies on pre-built models, limiting flexibility. Direct Lake breaks this compromise by offering:
- The speed of Import Mode, thanks to in-memory processing.
- The freshness of DirectQuery, with near real-time data access.
- The live access of Live Connection, without needing a separate model.
- Cost savings by eliminating data duplication.
Let’s dive into how Direct Lake works and why it’s a game-changer for analytics.
When Should You Use Direct Lake?
Direct Lake shines when you’re working with large datasets in OneLake and need both speed and freshness without the hassle of constant data imports.
Consider using Direct Lake if:
- You’re managing IT-driven analytics projects with a lake-centric architecture.
- Your data is (or will be) stored in Delta tables in OneLake.
- You need frequent data refreshes, fast query performance, and efficient resource use.
- Your data prep is already done in the data lake, and you want to deliver low-latency insights to business users.
- You want to leverage Power BI’s automatic page refresh for near real-time dashboards.
Direct Lake is perfect for scenarios where frequent refreshes or real-time insights are critical, offering scalability and performance without the overhead of traditional methods.
How Direct Lake Works
Direct Lake queries are powered by an in-memory cache of columns sourced from Delta tables in OneLake. These tables are stored as Parquet files, which organize data by columns for efficient querying. When a query is executed, the semantic model loads only the required columns into memory, ensuring fast performance.
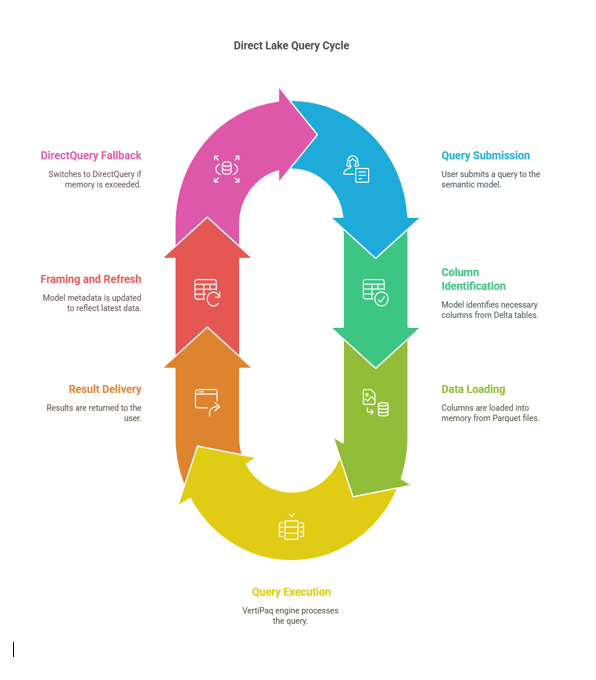
Step-by-Step Query Process
- Query Submission:
- A user submits a query (typically in DAX or MDX) to a Power BI semantic model configured in Direct Lake mode.
- The query originates from a Power BI report or another client interacting with the semantic model.
- Column Identification:
- The semantic model analyzes the query to determine which columns from the Delta tables are needed.
- Unlike Import mode, which loads entire datasets, Direct Lake loads only the specific columns required, reducing memory usage and improving efficiency.
- Data Loading into Memory:
- The required columns are retrieved from Parquet files stored in OneLake, which are part of the Delta table.
- The VertiPaq engine transcodes the Parquet data on-the-fly into a format compatible with its in-memory structure. Transcoding is necessary because Parquet’s compression differs from VertiPaq’s proprietary format, but the columnar nature of Parquet makes this process efficient.
- Data is loaded into an in-memory cache on a query-by-query basis, meaning only the data needed for the current query is cached.
- Query Execution:
- The VertiPaq engine processes the query using the in-memory cache, leveraging its advanced compression (e.g., Run-Length Encoding, Dictionary Encoding) and columnar storage for rapid execution.
- Queries are executed directly on the cached data without translating them into SQL, unlike DirectQuery, which enhances performance.
- Result Delivery:
- The query results are returned to the user, typically rendered as visuals in a Power BI report.
- Subsequent queries using the same columns benefit from the cached data, reducing load times unless the cache is evicted.
- Framing and Refresh:
- When a semantic model is refreshed, a framing operation occurs, updating the model’s metadata to reference the latest Parquet files in the Delta table. This is a low-cost operation, typically taking seconds, as it only updates metadata, not the entire dataset.
- Framing ensures the model reflects the latest data state, but queries only see data as of the most recent framing operation, providing point-in-time consistency.
- If automatic change detection is enabled, updates to Delta tables trigger framing to keep the model current.
- DirectQuery Fallback (if applicable):
- If a Delta table exceeds the memory capacity of the Fabric SKU (e.g., too many rows), Direct Lake seamlessly switches to DirectQuery mode, querying the SQL analytics endpoint of the lakehouse or warehouse.
- This fallback ensures functionality but may result in slower performance due to SQL query translation and execution.
Comparing Direct Lake with Other Storage Modes
To understand Direct Lake’s unique value, let’s compare it with other storage modes.
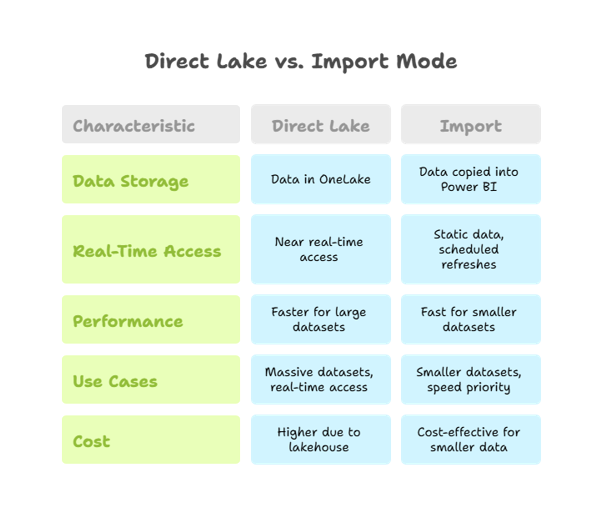
Direct Lake vs. Import Mode
- Data Storage:
- Direct Lake: Data stays in OneLake’s Delta tables, accessed via a lakehouse architecture. No data is copied into Power BI.
- Import: Data is fully copied into Power BI’s in-memory storage.
- Real-Time Access:
- Direct Lake: Offers near real-time access to external data without loading the entire dataset.
- Import: Data is static, updated only through scheduled refreshes.
- Performance:
- Direct Lake: Faster than DirectQuery for large datasets, thanks to optimized lakehouse storage.
- Import: Extremely fast for smaller datasets but struggles with large datasets that exceed memory limits.
- Use Cases:
- Direct Lake: Perfect for massive datasets needing real-time access and high performance.
- Import: Best for smaller datasets where speed matters more than freshness.
- Cost:
- Direct Lake: Higher costs due to lakehouse infrastructure.
- Import: More cost-effective for smaller datasets with no external query load.
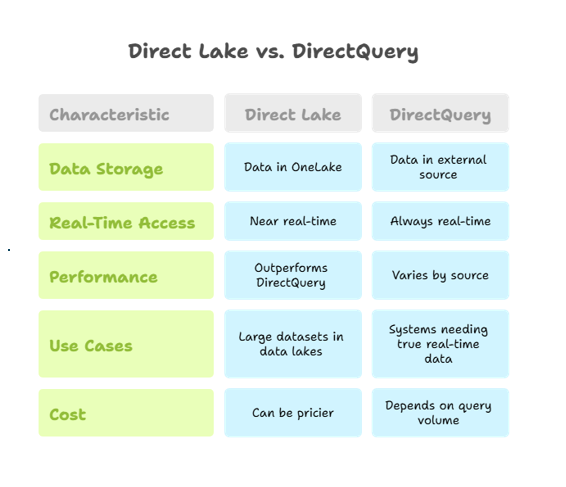
Direct Lake vs. DirectQuery
- Data Storage:
- Direct Lake: Data resides in OneLake’s Delta tables, optimized for fast retrieval.
- DirectQuery: Data stays in the external source, queried live with every report interaction.
- Real-Time Access:
- Direct Lake: Near real-time access without continuous queries to the source.
- DirectQuery: Always real-time, but performance depends on the source system.
- Performance:
- Direct Lake: Outperforms DirectQuery for large datasets due to optimized lakehouse retrieval.
- DirectQuery: Performance varies based on the source’s capacity and optimization.
- Use Cases:
- Direct Lake: Ideal for large datasets in data lakes needing near real-time access.
- DirectQuery: Suited for systems requiring true real-time data but may slow down with heavy queries.
- Cost:
- Direct Lake: Can be pricier due to lakehouse maintenance.
- DirectQuery: Costs depend on query volume and external database pricing.
Key Takeaways
- Direct Lake vs. Import: Choose Direct Lake for large datasets needing real-time access. Use Import for smaller, static datasets where speed is paramount.
- Direct Lake vs. Direct Query: Direct Lake offers better performance for large datasets, while DirectQuery is better for true real-time access with optimized sources.
Conclusion
- Direct Lake Storage Mode in Microsoft Fabric is a breakthrough for organizations seeking fast, fresh, and efficient analytics. By leveraging OneLake’s Delta tables and the VertiPaq engine, Direct Lake delivers the best of both worlds: the speed of in-memory processing and the freshness of real-time data access. Whether you’re managing massive datasets or building dynamic dashboards, Direct Lake empowers you to unlock real-time insights with ease.
- Ready to transform your analytics? Start exploring Direct Lake in Microsoft Fabric today and see how it can elevate your data-driven decisions.